Set up a finite mixture family for use in brms.
Arguments
- ...
One or more objects providing a description of the response distributions to be combined in the mixture model. These can be family functions, calls to family functions or character strings naming the families. For details of supported families see
brmsfamily.- flist
Optional list of objects, which are treated in the same way as objects passed via the
...argument.- nmix
Optional numeric vector specifying the number of times each family is repeated. If specified, it must have the same length as the number of families passed via
...andflist.- order
Ordering constraint to identify mixture components. If
'mu'orTRUE, population-level intercepts of the mean parameters are ordered in non-ordinal models and fixed to the same value in ordinal models (see details). If'none'orFALSE, no ordering constraint is applied. IfNULL(the default),orderis set to'mu'if all families are the same and'none'otherwise. Other ordering constraints may be implemented in the future.- refcat
Optional reference category for the mixing proportions. By default (
NULL), when the mixing proportions are predicted, all but one of them have to be modeled while the remaining one serves as the reference category (its linear predictor is fixed to zero) to identify the model. Ifrefcat = NA, no reference category is used and all mixing proportions are predicted via a 'softmax' transformation. This is analogous torefcat = NAincategoricalmodels. As the resulting model is only weakly identified, informative priors on thethetaparameters are strongly recommended (see the examples inbrmsformula).
Details
Most families supported by brms can be used to form mixtures. The response variable has to be valid for all components of the mixture family. Currently, the number of mixture components has to be specified by the user. It is not yet possible to estimate the number of mixture components from the data.
Ordering intercepts in mixtures of ordinal families is not possible as each family has itself a set of vector of intercepts (i.e. ordinal thresholds). Instead, brms will fix the vector of intercepts across components in ordinal mixtures, if desired, so that users can try to identify the mixture model via selective inclusion of predictors.
For most mixture models, you may want to specify priors on the
population-level intercepts via set_prior to improve
posterior inference. In addition, it is sometimes necessary to set init = 0
in the call to brm to allow chains to initialize properly.
For more details on the specification of mixture
models, see brmsformula.
Examples
# \dontrun{
## simulate some data
set.seed(1234)
dat <- data.frame(
y = c(rnorm(200), rnorm(100, 6)),
x = rnorm(300),
z = sample(0:1, 300, TRUE)
)
## fit a simple normal mixture model
mix <- mixture(gaussian, gaussian)
#> Setting order = 'mu' for mixtures of the same family.
prior <- c(
prior(normal(0, 7), Intercept, dpar = mu1),
prior(normal(5, 7), Intercept, dpar = mu2)
)
fit1 <- brm(bf(y ~ x + z), dat, family = mix,
prior = prior, chains = 2)
#> Compiling Stan program...
#> Start sampling
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 0.00019 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 1.9 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 1.458 seconds (Warm-up)
#> Chain 1: 1.076 seconds (Sampling)
#> Chain 1: 2.534 seconds (Total)
#> Chain 1:
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 2).
#> Chain 2:
#> Chain 2: Gradient evaluation took 0.000136 seconds
#> Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 1.36 seconds.
#> Chain 2: Adjust your expectations accordingly!
#> Chain 2:
#> Chain 2:
#> Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2:
#> Chain 2: Elapsed Time: 1.478 seconds (Warm-up)
#> Chain 2: 1.046 seconds (Sampling)
#> Chain 2: 2.524 seconds (Total)
#> Chain 2:
summary(fit1)
#> Family: mixture(gaussian, gaussian)
#> Links: mu1 = identity; mu2 = identity
#> Formula: y ~ x + z
#> Data: dat (Number of observations: 300)
#> Draws: 2 chains, each with iter = 2000; warmup = 1000; thin = 1;
#> total post-warmup draws = 2000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> mu1_Intercept 0.06 0.11 -0.16 0.28 1.00 3291 1654
#> mu2_Intercept 6.21 0.13 5.96 6.47 1.00 2480 1674
#> mu1_x 0.05 0.06 -0.07 0.18 1.00 3795 1580
#> mu1_z -0.17 0.15 -0.46 0.11 1.00 3703 1395
#> mu2_x -0.08 0.11 -0.29 0.12 1.00 4200 1339
#> mu2_z -0.09 0.19 -0.45 0.27 1.00 2648 1445
#>
#> Further Distributional Parameters:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> sigma1 1.04 0.05 0.94 1.15 1.00 3501 1646
#> sigma2 0.93 0.07 0.80 1.09 1.00 2748 1616
#> theta1 0.67 0.03 0.62 0.72 1.00 3187 1530
#> theta2 0.33 0.03 0.28 0.38 1.00 3187 1530
#>
#> Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).
pp_check(fit1)
#> Using 10 posterior draws for ppc type 'dens_overlay' by default.
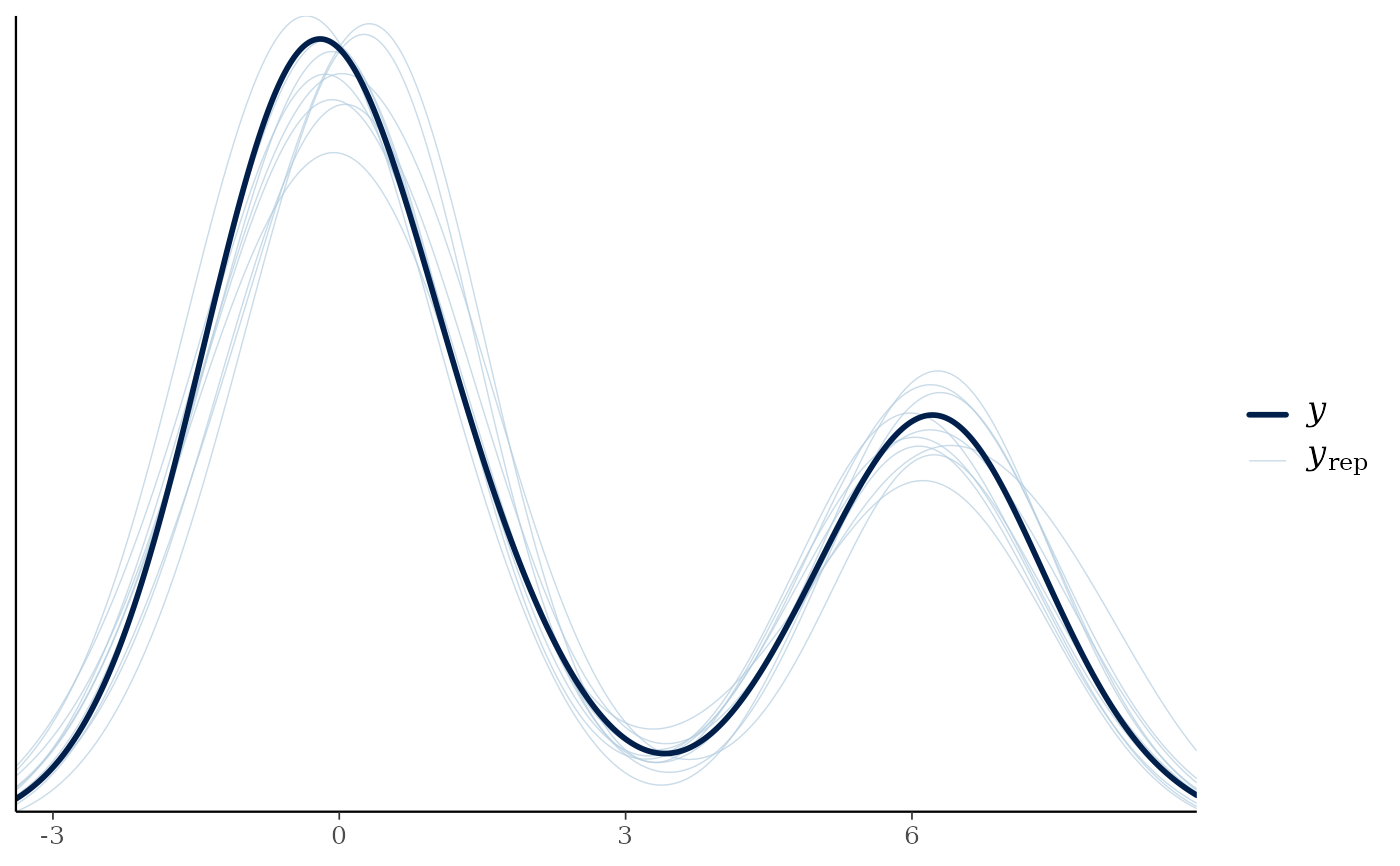 ## use different predictors for the components
fit2 <- brm(bf(y ~ 1, mu1 ~ x, mu2 ~ z), dat, family = mix,
prior = prior, chains = 2)
#> Compiling Stan program...
#> Start sampling
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 0.000151 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 1.51 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 1.284 seconds (Warm-up)
#> Chain 1: 1.046 seconds (Sampling)
#> Chain 1: 2.33 seconds (Total)
#> Chain 1:
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 2).
#> Chain 2:
#> Chain 2: Gradient evaluation took 0.000164 seconds
#> Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 1.64 seconds.
#> Chain 2: Adjust your expectations accordingly!
#> Chain 2:
#> Chain 2:
#> Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2:
#> Chain 2: Elapsed Time: 1.461 seconds (Warm-up)
#> Chain 2: 1.097 seconds (Sampling)
#> Chain 2: 2.558 seconds (Total)
#> Chain 2:
#> Warning: The largest R-hat is 1.83, indicating chains have not mixed.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#r-hat
#> Warning: Bulk Effective Samples Size (ESS) is too low, indicating posterior means and medians may be unreliable.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#bulk-ess
#> Warning: Tail Effective Samples Size (ESS) is too low, indicating posterior variances and tail quantiles may be unreliable.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#tail-ess
summary(fit2)
#> Warning: Inference for the model posterior has not converged (some Rhats are > 1.05). Be careful when analysing the results! We recommend running more iterations or setting stronger priors.
#> Family: mixture(gaussian, gaussian)
#> Links: mu1 = identity; mu2 = identity
#> Formula: y ~ 1
#> mu1 ~ x
#> mu2 ~ z
#> Data: dat (Number of observations: 300)
#> Draws: 2 chains, each with iter = 2000; warmup = 1000; thin = 1;
#> total post-warmup draws = 2000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> mu1_Intercept -0.04 0.09 -0.21 0.13 1.01 1795 1299
#> mu2_Intercept 3.19 3.04 -0.07 6.45 1.83 3 61
#> mu1_x -0.09 0.33 -0.91 0.41 1.39 13 80
#> mu2_z -0.17 0.20 -0.55 0.22 1.10 13 141
#>
#> Further Distributional Parameters:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> sigma1 3.03 2.01 0.95 5.57 1.83 3 85
#> sigma2 0.85 0.11 0.66 1.06 1.53 4 77
#> theta1 0.60 0.08 0.47 0.71 1.80 3 79
#> theta2 0.40 0.08 0.29 0.53 1.80 3 79
#>
#> Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).
## fix the mixing proportions
fit3 <- brm(bf(y ~ x + z, theta1 = 1, theta2 = 2),
dat, family = mix, prior = prior,
init = 0, chains = 2)
#> Compiling Stan program...
#> Start sampling
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 0.000139 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 1.39 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 1.089 seconds (Warm-up)
#> Chain 1: 0.971 seconds (Sampling)
#> Chain 1: 2.06 seconds (Total)
#> Chain 1:
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 2).
#> Chain 2:
#> Chain 2: Gradient evaluation took 0.000124 seconds
#> Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 1.24 seconds.
#> Chain 2: Adjust your expectations accordingly!
#> Chain 2:
#> Chain 2:
#> Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2:
#> Chain 2: Elapsed Time: 1.068 seconds (Warm-up)
#> Chain 2: 0.905 seconds (Sampling)
#> Chain 2: 1.973 seconds (Total)
#> Chain 2:
summary(fit3)
#> Family: mixture(gaussian, gaussian)
#> Links: mu1 = identity; mu2 = identity
#> Formula: y ~ x + z
#> theta1 = 0.33
#> theta2 = 0.67
#> Data: dat (Number of observations: 300)
#> Draws: 2 chains, each with iter = 2000; warmup = 1000; thin = 1;
#> total post-warmup draws = 2000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> mu1_Intercept -0.19 0.11 -0.41 0.01 1.00 3052 1809
#> mu2_Intercept 4.49 0.45 3.61 5.34 1.00 2983 1642
#> mu1_x -0.01 0.08 -0.15 0.15 1.00 3496 1594
#> mu1_z -0.23 0.15 -0.51 0.08 1.00 3365 1739
#> mu2_x -0.22 0.28 -0.77 0.32 1.00 2940 1637
#> mu2_z -1.28 0.57 -2.41 -0.10 1.00 2432 1418
#>
#> Further Distributional Parameters:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> sigma1 0.68 0.06 0.56 0.81 1.00 2862 1639
#> sigma2 2.98 0.19 2.64 3.35 1.00 2422 1515
#>
#> Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).
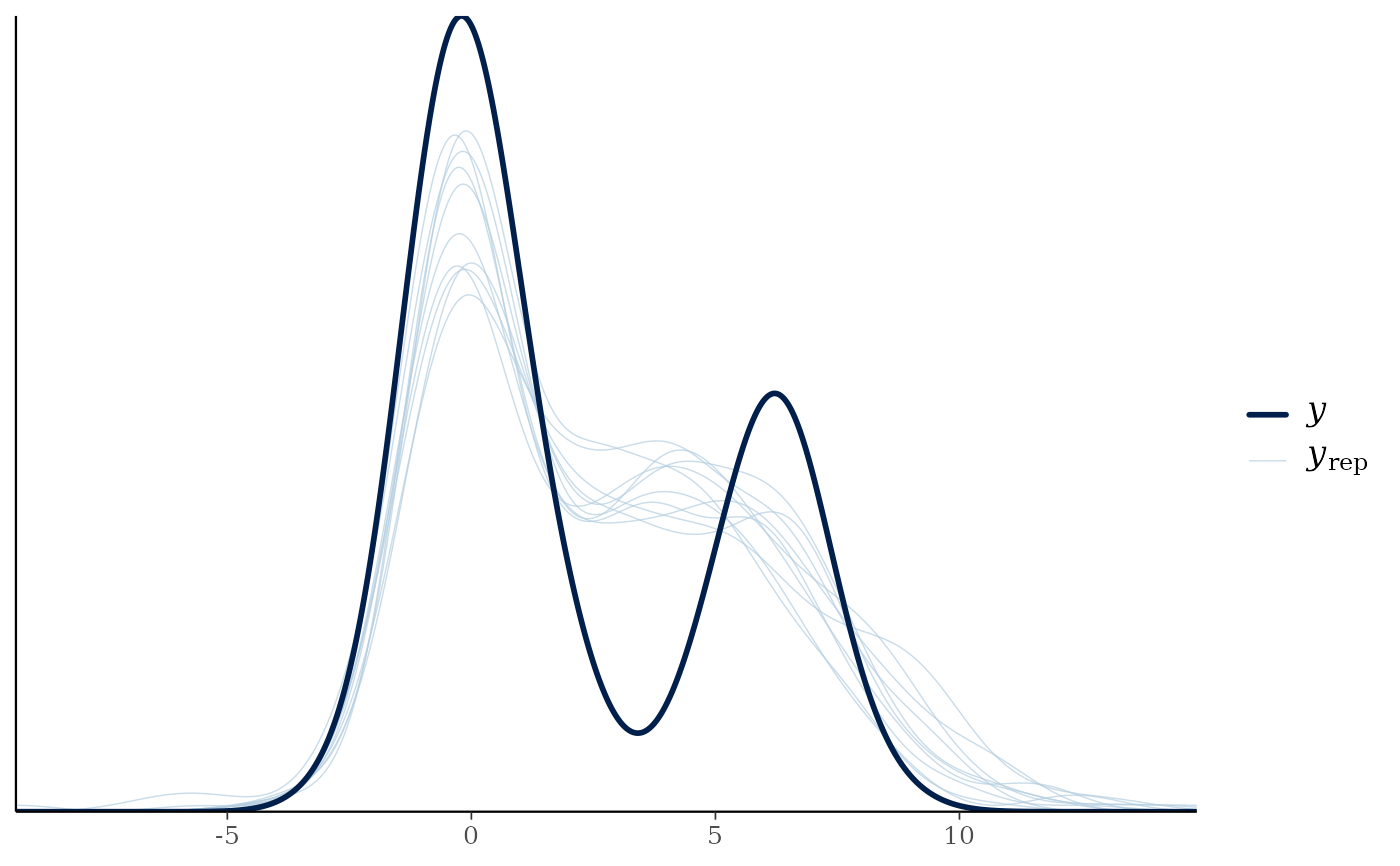
pp_check(fit3)
#> Using 10 posterior draws for ppc type 'dens_overlay' by default.
## use different predictors for the components
fit2 <- brm(bf(y ~ 1, mu1 ~ x, mu2 ~ z), dat, family = mix,
prior = prior, chains = 2)
#> Compiling Stan program...
#> Start sampling
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 0.000151 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 1.51 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 1.284 seconds (Warm-up)
#> Chain 1: 1.046 seconds (Sampling)
#> Chain 1: 2.33 seconds (Total)
#> Chain 1:
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 2).
#> Chain 2:
#> Chain 2: Gradient evaluation took 0.000164 seconds
#> Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 1.64 seconds.
#> Chain 2: Adjust your expectations accordingly!
#> Chain 2:
#> Chain 2:
#> Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2:
#> Chain 2: Elapsed Time: 1.461 seconds (Warm-up)
#> Chain 2: 1.097 seconds (Sampling)
#> Chain 2: 2.558 seconds (Total)
#> Chain 2:
#> Warning: The largest R-hat is 1.83, indicating chains have not mixed.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#r-hat
#> Warning: Bulk Effective Samples Size (ESS) is too low, indicating posterior means and medians may be unreliable.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#bulk-ess
#> Warning: Tail Effective Samples Size (ESS) is too low, indicating posterior variances and tail quantiles may be unreliable.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#tail-ess
summary(fit2)
#> Warning: Inference for the model posterior has not converged (some Rhats are > 1.05). Be careful when analysing the results! We recommend running more iterations or setting stronger priors.
#> Family: mixture(gaussian, gaussian)
#> Links: mu1 = identity; mu2 = identity
#> Formula: y ~ 1
#> mu1 ~ x
#> mu2 ~ z
#> Data: dat (Number of observations: 300)
#> Draws: 2 chains, each with iter = 2000; warmup = 1000; thin = 1;
#> total post-warmup draws = 2000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> mu1_Intercept -0.04 0.09 -0.21 0.13 1.01 1795 1299
#> mu2_Intercept 3.19 3.04 -0.07 6.45 1.83 3 61
#> mu1_x -0.09 0.33 -0.91 0.41 1.39 13 80
#> mu2_z -0.17 0.20 -0.55 0.22 1.10 13 141
#>
#> Further Distributional Parameters:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> sigma1 3.03 2.01 0.95 5.57 1.83 3 85
#> sigma2 0.85 0.11 0.66 1.06 1.53 4 77
#> theta1 0.60 0.08 0.47 0.71 1.80 3 79
#> theta2 0.40 0.08 0.29 0.53 1.80 3 79
#>
#> Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).
## fix the mixing proportions
fit3 <- brm(bf(y ~ x + z, theta1 = 1, theta2 = 2),
dat, family = mix, prior = prior,
init = 0, chains = 2)
#> Compiling Stan program...
#> Start sampling
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 0.000139 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 1.39 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 1.089 seconds (Warm-up)
#> Chain 1: 0.971 seconds (Sampling)
#> Chain 1: 2.06 seconds (Total)
#> Chain 1:
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 2).
#> Chain 2:
#> Chain 2: Gradient evaluation took 0.000124 seconds
#> Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 1.24 seconds.
#> Chain 2: Adjust your expectations accordingly!
#> Chain 2:
#> Chain 2:
#> Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2:
#> Chain 2: Elapsed Time: 1.068 seconds (Warm-up)
#> Chain 2: 0.905 seconds (Sampling)
#> Chain 2: 1.973 seconds (Total)
#> Chain 2:
summary(fit3)
#> Family: mixture(gaussian, gaussian)
#> Links: mu1 = identity; mu2 = identity
#> Formula: y ~ x + z
#> theta1 = 0.33
#> theta2 = 0.67
#> Data: dat (Number of observations: 300)
#> Draws: 2 chains, each with iter = 2000; warmup = 1000; thin = 1;
#> total post-warmup draws = 2000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> mu1_Intercept -0.19 0.11 -0.41 0.01 1.00 3052 1809
#> mu2_Intercept 4.49 0.45 3.61 5.34 1.00 2983 1642
#> mu1_x -0.01 0.08 -0.15 0.15 1.00 3496 1594
#> mu1_z -0.23 0.15 -0.51 0.08 1.00 3365 1739
#> mu2_x -0.22 0.28 -0.77 0.32 1.00 2940 1637
#> mu2_z -1.28 0.57 -2.41 -0.10 1.00 2432 1418
#>
#> Further Distributional Parameters:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> sigma1 0.68 0.06 0.56 0.81 1.00 2862 1639
#> sigma2 2.98 0.19 2.64 3.35 1.00 2422 1515
#>
#> Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).
pp_check(fit3)
#> Using 10 posterior draws for ppc type 'dens_overlay' by default.
 ## predict the mixing proportions
fit4 <- brm(bf(y ~ x + z, theta2 ~ x),
dat, family = mix, prior = prior,
init = 0, chains = 2)
#> Compiling Stan program...
#> Start sampling
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 0.000238 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 2.38 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 2.089 seconds (Warm-up)
#> Chain 1: 1.56 seconds (Sampling)
#> Chain 1: 3.649 seconds (Total)
#> Chain 1:
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 2).
#> Chain 2:
#> Chain 2: Gradient evaluation took 0.000226 seconds
#> Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 2.26 seconds.
#> Chain 2: Adjust your expectations accordingly!
#> Chain 2:
#> Chain 2:
#> Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2:
#> Chain 2: Elapsed Time: 2.144 seconds (Warm-up)
#> Chain 2: 1.592 seconds (Sampling)
#> Chain 2: 3.736 seconds (Total)
#> Chain 2:
summary(fit4)
#> Family: mixture(gaussian, gaussian)
#> Links: mu1 = identity; mu2 = identity; theta2 = identity
#> Formula: y ~ x + z
#> theta2 ~ x
#> Data: dat (Number of observations: 300)
#> Draws: 2 chains, each with iter = 2000; warmup = 1000; thin = 1;
#> total post-warmup draws = 2000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> mu1_Intercept 0.05 0.11 -0.17 0.28 1.00 2218 1569
#> mu2_Intercept 6.21 0.13 5.95 6.48 1.00 3161 1593
#> theta2_Intercept -0.71 0.13 -0.98 -0.46 1.00 2999 1448
#> mu1_x 0.06 0.07 -0.08 0.19 1.00 3345 1701
#> mu1_z -0.17 0.14 -0.45 0.11 1.00 2720 1473
#> mu2_x -0.08 0.10 -0.28 0.12 1.00 3747 1365
#> mu2_z -0.09 0.19 -0.48 0.28 1.00 2677 1131
#> theta2_x -0.11 0.12 -0.34 0.12 1.00 3585 1564
#>
#> Further Distributional Parameters:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> sigma1 1.04 0.05 0.94 1.15 1.00 3183 1443
#> sigma2 0.93 0.07 0.80 1.08 1.00 3608 1640
#>
#> Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).
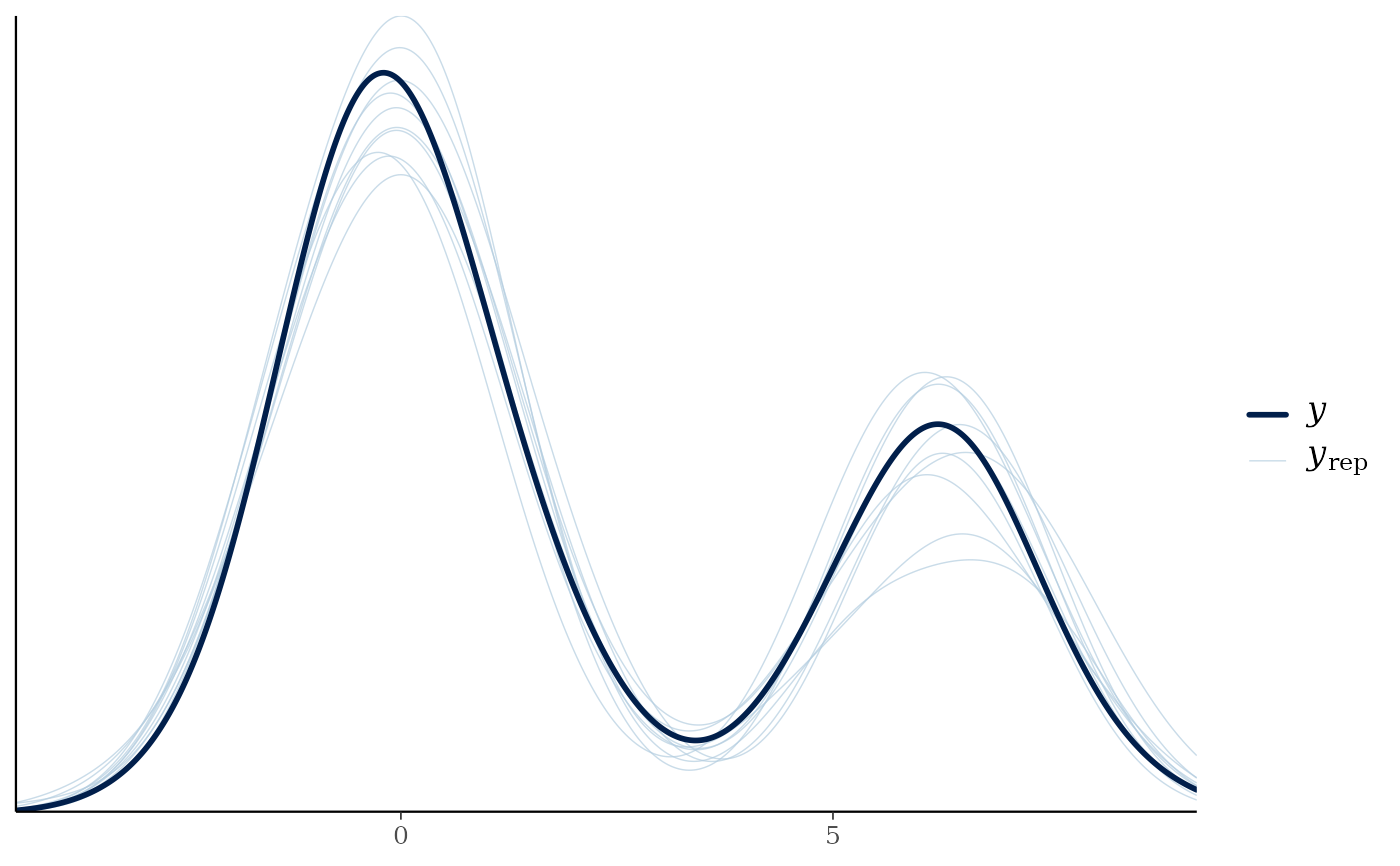
pp_check(fit4)
#> Using 10 posterior draws for ppc type 'dens_overlay' by default.
## predict the mixing proportions
fit4 <- brm(bf(y ~ x + z, theta2 ~ x),
dat, family = mix, prior = prior,
init = 0, chains = 2)
#> Compiling Stan program...
#> Start sampling
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 0.000238 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 2.38 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 2.089 seconds (Warm-up)
#> Chain 1: 1.56 seconds (Sampling)
#> Chain 1: 3.649 seconds (Total)
#> Chain 1:
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 2).
#> Chain 2:
#> Chain 2: Gradient evaluation took 0.000226 seconds
#> Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 2.26 seconds.
#> Chain 2: Adjust your expectations accordingly!
#> Chain 2:
#> Chain 2:
#> Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2:
#> Chain 2: Elapsed Time: 2.144 seconds (Warm-up)
#> Chain 2: 1.592 seconds (Sampling)
#> Chain 2: 3.736 seconds (Total)
#> Chain 2:
summary(fit4)
#> Family: mixture(gaussian, gaussian)
#> Links: mu1 = identity; mu2 = identity; theta2 = identity
#> Formula: y ~ x + z
#> theta2 ~ x
#> Data: dat (Number of observations: 300)
#> Draws: 2 chains, each with iter = 2000; warmup = 1000; thin = 1;
#> total post-warmup draws = 2000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> mu1_Intercept 0.05 0.11 -0.17 0.28 1.00 2218 1569
#> mu2_Intercept 6.21 0.13 5.95 6.48 1.00 3161 1593
#> theta2_Intercept -0.71 0.13 -0.98 -0.46 1.00 2999 1448
#> mu1_x 0.06 0.07 -0.08 0.19 1.00 3345 1701
#> mu1_z -0.17 0.14 -0.45 0.11 1.00 2720 1473
#> mu2_x -0.08 0.10 -0.28 0.12 1.00 3747 1365
#> mu2_z -0.09 0.19 -0.48 0.28 1.00 2677 1131
#> theta2_x -0.11 0.12 -0.34 0.12 1.00 3585 1564
#>
#> Further Distributional Parameters:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> sigma1 1.04 0.05 0.94 1.15 1.00 3183 1443
#> sigma2 0.93 0.07 0.80 1.08 1.00 3608 1640
#>
#> Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).
pp_check(fit4)
#> Using 10 posterior draws for ppc type 'dens_overlay' by default.
 ## predict all mixing proportions without a reference category
## (requires informative priors on the theta parameters)
mix_na <- mixture(gaussian, gaussian, refcat = NA)
#> Setting order = 'mu' for mixtures of the same family.
theta_prior <- c(prior, prior(normal(0, 1), Intercept, dpar = theta1),
prior(normal(0, 1), Intercept, dpar = theta2))
fit5 <- brm(bf(y ~ x + z, theta1 ~ x, theta2 ~ x),
dat, family = mix_na, prior = theta_prior,
init = 0, chains = 2)
#> Compiling Stan program...
#> Start sampling
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 0.000237 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 2.37 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 170.097 seconds (Warm-up)
#> Chain 1: 201.184 seconds (Sampling)
#> Chain 1: 371.281 seconds (Total)
#> Chain 1:
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 2).
#> Chain 2:
#> Chain 2: Gradient evaluation took 0.000242 seconds
#> Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 2.42 seconds.
#> Chain 2: Adjust your expectations accordingly!
#> Chain 2:
#> Chain 2:
#> Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2:
#> Chain 2: Elapsed Time: 168.53 seconds (Warm-up)
#> Chain 2: 205.895 seconds (Sampling)
#> Chain 2: 374.425 seconds (Total)
#> Chain 2:
#> Warning: There were 222 divergent transitions after warmup. See
#> https://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
#> to find out why this is a problem and how to eliminate them.
#> Warning: There were 1776 transitions after warmup that exceeded the maximum treedepth. Increase max_treedepth above 10. See
#> https://mc-stan.org/misc/warnings.html#maximum-treedepth-exceeded
#> Warning: Examine the pairs() plot to diagnose sampling problems
#> Warning: Bulk Effective Samples Size (ESS) is too low, indicating posterior means and medians may be unreliable.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#bulk-ess
#> Warning: Tail Effective Samples Size (ESS) is too low, indicating posterior variances and tail quantiles may be unreliable.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#tail-ess
summary(fit5)
#> Warning: There were 222 divergent transitions after warmup. Increasing adapt_delta above 0.8 may help. See http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
#> Family: mixture(gaussian, gaussian)
#> Links: mu1 = identity; mu2 = identity; theta1 = identity; theta2 = identity
#> Formula: y ~ x + z
#> theta1 ~ x
#> theta2 ~ x
#> Data: dat (Number of observations: 300)
#> Draws: 2 chains, each with iter = 2000; warmup = 1000; thin = 1;
#> total post-warmup draws = 2000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> mu1_Intercept 0.06 0.12 -0.16 0.29 1.03 50 165
#> mu2_Intercept 6.21 0.12 5.95 6.45 1.01 88 231
#> theta1_Intercept 1.38 6.62 -10.98 11.58 1.04 32 75
#> theta2_Intercept 0.67 6.62 -11.78 10.88 1.04 32 75
#> mu1_x 0.07 0.07 -0.07 0.21 1.01 105 146
#> mu1_z -0.17 0.15 -0.48 0.12 1.01 97 122
#> mu2_x -0.08 0.10 -0.28 0.12 1.01 83 258
#> mu2_z -0.10 0.18 -0.43 0.26 1.02 91 206
#> theta1_x 16.64 117.47 -202.95 205.84 1.05 32 90
#> theta2_x 16.53 117.48 -202.88 205.84 1.05 32 93
#>
#> Further Distributional Parameters:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> sigma1 1.04 0.05 0.95 1.14 1.01 98 212
#> sigma2 0.93 0.09 0.80 1.12 1.02 72 73
#>
#> Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).
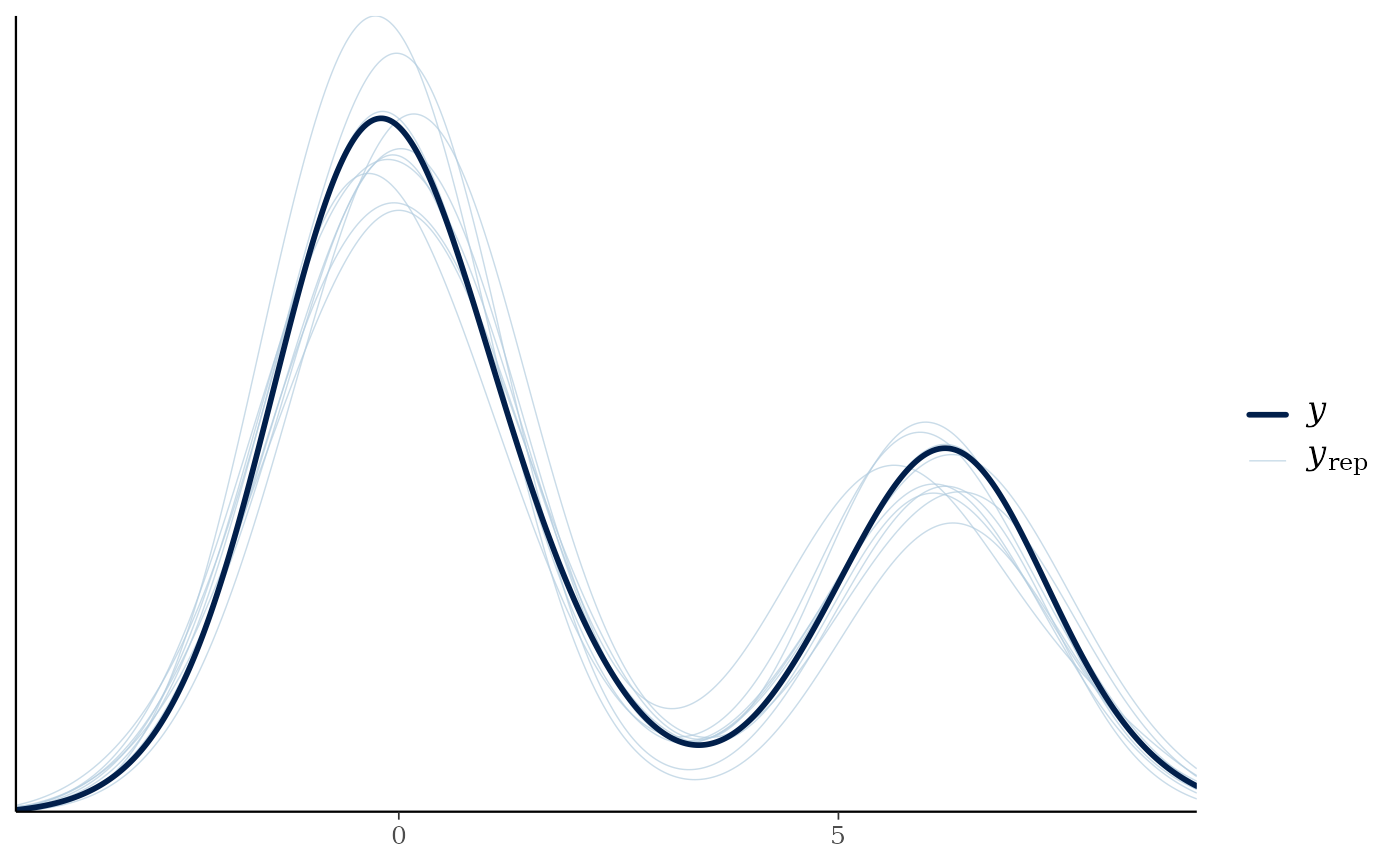
pp_check(fit5)
#> Using 10 posterior draws for ppc type 'dens_overlay' by default.
## predict all mixing proportions without a reference category
## (requires informative priors on the theta parameters)
mix_na <- mixture(gaussian, gaussian, refcat = NA)
#> Setting order = 'mu' for mixtures of the same family.
theta_prior <- c(prior, prior(normal(0, 1), Intercept, dpar = theta1),
prior(normal(0, 1), Intercept, dpar = theta2))
fit5 <- brm(bf(y ~ x + z, theta1 ~ x, theta2 ~ x),
dat, family = mix_na, prior = theta_prior,
init = 0, chains = 2)
#> Compiling Stan program...
#> Start sampling
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 0.000237 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 2.37 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 170.097 seconds (Warm-up)
#> Chain 1: 201.184 seconds (Sampling)
#> Chain 1: 371.281 seconds (Total)
#> Chain 1:
#>
#> SAMPLING FOR MODEL 'anon_model' NOW (CHAIN 2).
#> Chain 2:
#> Chain 2: Gradient evaluation took 0.000242 seconds
#> Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 2.42 seconds.
#> Chain 2: Adjust your expectations accordingly!
#> Chain 2:
#> Chain 2:
#> Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2:
#> Chain 2: Elapsed Time: 168.53 seconds (Warm-up)
#> Chain 2: 205.895 seconds (Sampling)
#> Chain 2: 374.425 seconds (Total)
#> Chain 2:
#> Warning: There were 222 divergent transitions after warmup. See
#> https://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
#> to find out why this is a problem and how to eliminate them.
#> Warning: There were 1776 transitions after warmup that exceeded the maximum treedepth. Increase max_treedepth above 10. See
#> https://mc-stan.org/misc/warnings.html#maximum-treedepth-exceeded
#> Warning: Examine the pairs() plot to diagnose sampling problems
#> Warning: Bulk Effective Samples Size (ESS) is too low, indicating posterior means and medians may be unreliable.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#bulk-ess
#> Warning: Tail Effective Samples Size (ESS) is too low, indicating posterior variances and tail quantiles may be unreliable.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#tail-ess
summary(fit5)
#> Warning: There were 222 divergent transitions after warmup. Increasing adapt_delta above 0.8 may help. See http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
#> Family: mixture(gaussian, gaussian)
#> Links: mu1 = identity; mu2 = identity; theta1 = identity; theta2 = identity
#> Formula: y ~ x + z
#> theta1 ~ x
#> theta2 ~ x
#> Data: dat (Number of observations: 300)
#> Draws: 2 chains, each with iter = 2000; warmup = 1000; thin = 1;
#> total post-warmup draws = 2000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> mu1_Intercept 0.06 0.12 -0.16 0.29 1.03 50 165
#> mu2_Intercept 6.21 0.12 5.95 6.45 1.01 88 231
#> theta1_Intercept 1.38 6.62 -10.98 11.58 1.04 32 75
#> theta2_Intercept 0.67 6.62 -11.78 10.88 1.04 32 75
#> mu1_x 0.07 0.07 -0.07 0.21 1.01 105 146
#> mu1_z -0.17 0.15 -0.48 0.12 1.01 97 122
#> mu2_x -0.08 0.10 -0.28 0.12 1.01 83 258
#> mu2_z -0.10 0.18 -0.43 0.26 1.02 91 206
#> theta1_x 16.64 117.47 -202.95 205.84 1.05 32 90
#> theta2_x 16.53 117.48 -202.88 205.84 1.05 32 93
#>
#> Further Distributional Parameters:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> sigma1 1.04 0.05 0.95 1.14 1.01 98 212
#> sigma2 0.93 0.09 0.80 1.12 1.02 72 73
#>
#> Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).
pp_check(fit5)
#> Using 10 posterior draws for ppc type 'dens_overlay' by default.
 ## compare model fit
loo(fit1, fit2, fit3, fit4)
#> Output of model 'fit1':
#>
#> Computed from 2000 by 300 log-likelihood matrix.
#>
#> Estimate SE
#> elpd_loo -619.8 13.8
#> p_loo 9.3 1.0
#> looic 1239.7 27.7
#> ------
#> MCSE of elpd_loo is 0.1.
#> MCSE and ESS estimates assume MCMC draws (r_eff in [1.1, 2.0]).
#>
#> All Pareto k estimates are good (k < 0.7).
#> See help('pareto-k-diagnostic') for details.
#>
#> Output of model 'fit2':
#>
#> Computed from 2000 by 300 log-likelihood matrix.
#>
#> Estimate SE
#> elpd_loo -721.2 17.0
#> p_loo 71.6 5.8
#> looic 1442.3 34.1
#> ------
#> MCSE of elpd_loo is 4.7.
#> MCSE and ESS estimates assume MCMC draws (r_eff in [0.0, 1.4]).
#>
#> All Pareto k estimates are good (k < 0.7).
#> See help('pareto-k-diagnostic') for details.
#>
#> Output of model 'fit3':
#>
#> Computed from 2000 by 300 log-likelihood matrix.
#>
#> Estimate SE
#> elpd_loo -683.6 11.1
#> p_loo 7.6 0.6
#> looic 1367.2 22.2
#> ------
#> MCSE of elpd_loo is 0.1.
#> MCSE and ESS estimates assume MCMC draws (r_eff in [0.9, 1.8]).
#>
#> All Pareto k estimates are good (k < 0.7).
#> See help('pareto-k-diagnostic') for details.
#>
#> Output of model 'fit4':
#>
#> Computed from 2000 by 300 log-likelihood matrix.
#>
#> Estimate SE
#> elpd_loo -620.6 13.9
#> p_loo 10.4 1.0
#> looic 1241.1 27.7
#> ------
#> MCSE of elpd_loo is 0.1.
#> MCSE and ESS estimates assume MCMC draws (r_eff in [1.1, 1.9]).
#>
#> All Pareto k estimates are good (k < 0.7).
#> See help('pareto-k-diagnostic') for details.
#>
#> Model comparisons:
#> model elpd_diff se_diff p_worse diag_diff diag_elpd
#> fit1 0.0 0.0 NA
#> fit4 -0.7 0.9 0.80 |elpd_diff| < 4
#> fit3 -63.8 9.9 1.00
#> fit2 -101.3 10.2 1.00
#>
#> Diagnostic flags present.
#> See ?`loo-glossary` (sections `diag_diff` and `diag_elpd`)
#> or https://mc-stan.org/loo/reference/loo-glossary.html.
# }
## compare model fit
loo(fit1, fit2, fit3, fit4)
#> Output of model 'fit1':
#>
#> Computed from 2000 by 300 log-likelihood matrix.
#>
#> Estimate SE
#> elpd_loo -619.8 13.8
#> p_loo 9.3 1.0
#> looic 1239.7 27.7
#> ------
#> MCSE of elpd_loo is 0.1.
#> MCSE and ESS estimates assume MCMC draws (r_eff in [1.1, 2.0]).
#>
#> All Pareto k estimates are good (k < 0.7).
#> See help('pareto-k-diagnostic') for details.
#>
#> Output of model 'fit2':
#>
#> Computed from 2000 by 300 log-likelihood matrix.
#>
#> Estimate SE
#> elpd_loo -721.2 17.0
#> p_loo 71.6 5.8
#> looic 1442.3 34.1
#> ------
#> MCSE of elpd_loo is 4.7.
#> MCSE and ESS estimates assume MCMC draws (r_eff in [0.0, 1.4]).
#>
#> All Pareto k estimates are good (k < 0.7).
#> See help('pareto-k-diagnostic') for details.
#>
#> Output of model 'fit3':
#>
#> Computed from 2000 by 300 log-likelihood matrix.
#>
#> Estimate SE
#> elpd_loo -683.6 11.1
#> p_loo 7.6 0.6
#> looic 1367.2 22.2
#> ------
#> MCSE of elpd_loo is 0.1.
#> MCSE and ESS estimates assume MCMC draws (r_eff in [0.9, 1.8]).
#>
#> All Pareto k estimates are good (k < 0.7).
#> See help('pareto-k-diagnostic') for details.
#>
#> Output of model 'fit4':
#>
#> Computed from 2000 by 300 log-likelihood matrix.
#>
#> Estimate SE
#> elpd_loo -620.6 13.9
#> p_loo 10.4 1.0
#> looic 1241.1 27.7
#> ------
#> MCSE of elpd_loo is 0.1.
#> MCSE and ESS estimates assume MCMC draws (r_eff in [1.1, 1.9]).
#>
#> All Pareto k estimates are good (k < 0.7).
#> See help('pareto-k-diagnostic') for details.
#>
#> Model comparisons:
#> model elpd_diff se_diff p_worse diag_diff diag_elpd
#> fit1 0.0 0.0 NA
#> fit4 -0.7 0.9 0.80 |elpd_diff| < 4
#> fit3 -63.8 9.9 1.00
#> fit2 -101.3 10.2 1.00
#>
#> Diagnostic flags present.
#> See ?`loo-glossary` (sections `diag_diff` and `diag_elpd`)
#> or https://mc-stan.org/loo/reference/loo-glossary.html.
# }